Contribution 1
Construct OlaBench, a real-world benchmark for industrial customer service that evaluates deployable dialogue behavior across multi-dimensional service quality, critical risk, hallucination, and latency.
*Equal contribution. †Corresponding author.
Existing benchmarks and training pipelines for industrial intelligent customer service (ICS) remain misaligned with real-world dialogue requirements, overemphasizing verifiable task success while under-measuring subjective service quality and realistic failure modes, leaving a gap between offline gains and deployable dialogue behavior. We close this gap with a benchmark-to-optimization loop: we first introduce OlaBench, an ICS benchmark spanning retrieval-augmented generation, workflow-based systems, and agentic settings, which evaluates service capability, safety, and latency sensitivity; moreover, motivated by OlaBench results showing state-of-the-art LLMs still fall short, we propose OlaMind, which distills reusable reasoning patterns and service strategies from expert dialogues and applies rubric-aware staged exploration-exploitation reinforcement learning to improve model capability. OlaMind surpasses GPT-5.2 and Gemini 3 Pro on OlaBench (83.64 vs. 70.58/70.84) and, in online A/B tests, delivers an average +23.67% issue resolution and -6.6% human transfer rate versus the baseline, bridging offline gains to deployment. Together, OlaBench and OlaMind advance ICS systems toward more anthropomorphic, professional, and reliable deployment.
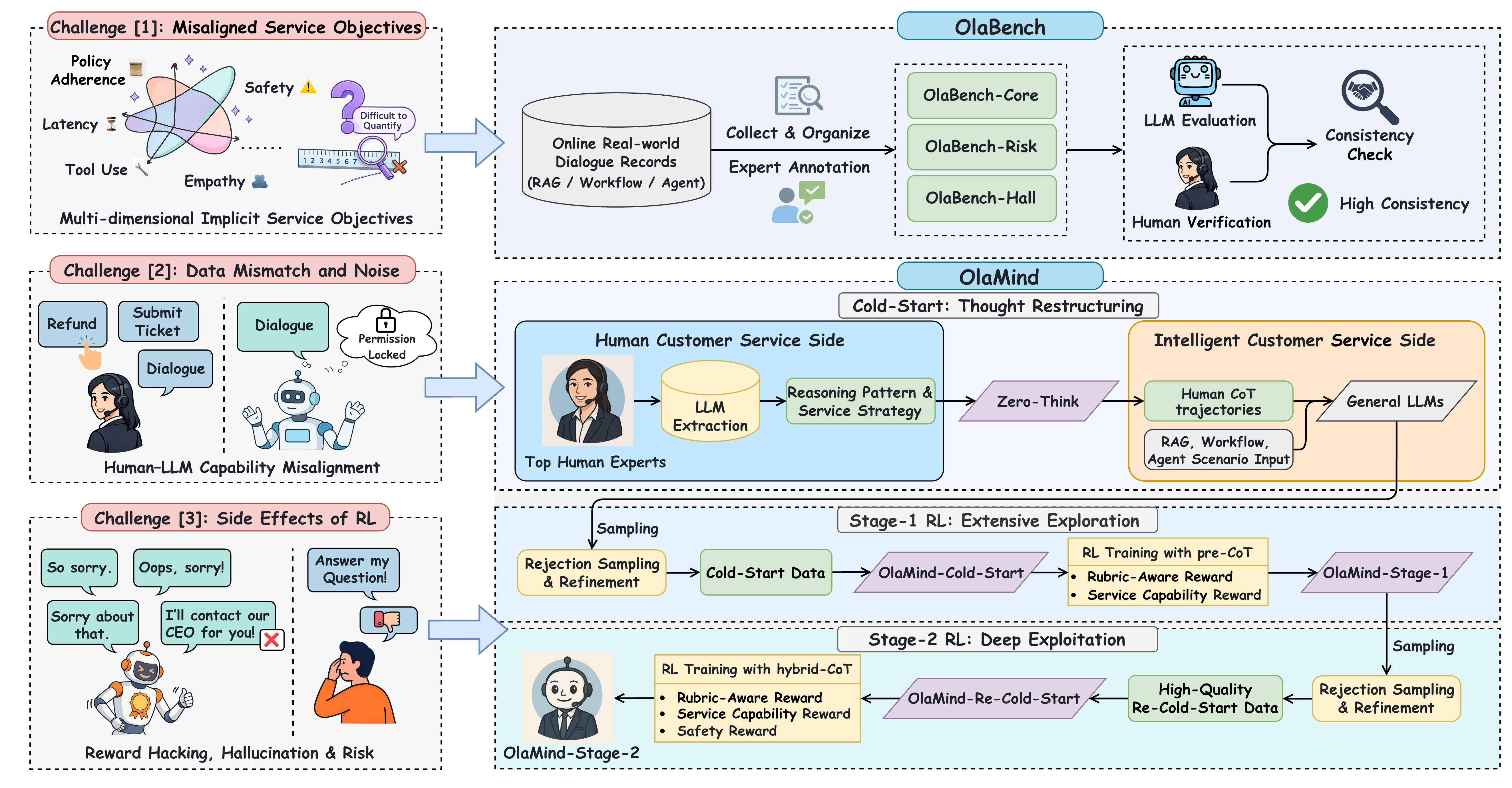
Industrial intelligent customer service requires dialogue systems that are effective, human-like, professionally competent, policy-compliant, and safe, all under strict latency and service constraints. Existing service-agent benchmarks predominantly emphasize task completion and tool correctness. Several critical dimensions remain underexplored, including hallucinations hidden behind fluent language, latency overhead from reasoning-intensive generation, and long-horizon adherence to service strategies and policies in multi-turn dialogues. As a result, strong offline performance remains a weak indicator of reliable real-world deployment.
To bridge this gap, the paper introduces OlaBench, a real-world benchmark for deployable dialogue behavior across service capability, safety, and latency-awareness in RAG, workflow, and agent settings. Motivated by OlaBench results showing that state-of-the-art LLMs still fall short, it further proposes OlaMind, which distills reusable reasoning patterns and service strategies from expert dialogues and refines them through rubric-aware exploration-exploitation reinforcement learning. The main contributions are as follows:
Construct OlaBench, a real-world benchmark for industrial customer service that evaluates deployable dialogue behavior across multi-dimensional service quality, critical risk, hallucination, and latency.
Propose OlaMind, a training paradigm that bootstraps models with expert reasoning patterns and service strategies, and then progressively elicits effective behaviors via exploration-exploitation reinforcement learning.
Demonstrate that OlaMind achieves state-of-the-art performance on OlaBench and delivers consistent, measurable improvements in real-world deployment with live users.
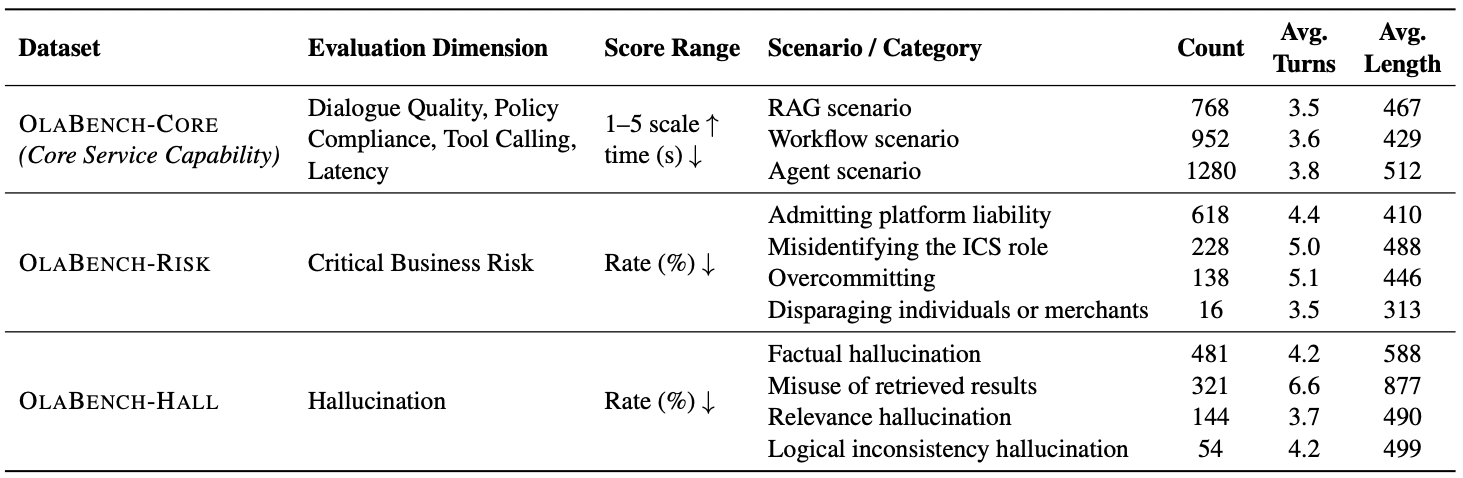
Grounded in real challenges encountered in industrial practice, OlaBench is derived from real-world industrial customer-service data to evaluate models across multi-dimensional service capability, safety, and latency-awareness. It consists of three subsets spanning three application scenarios and evaluates six sub-capabilities.
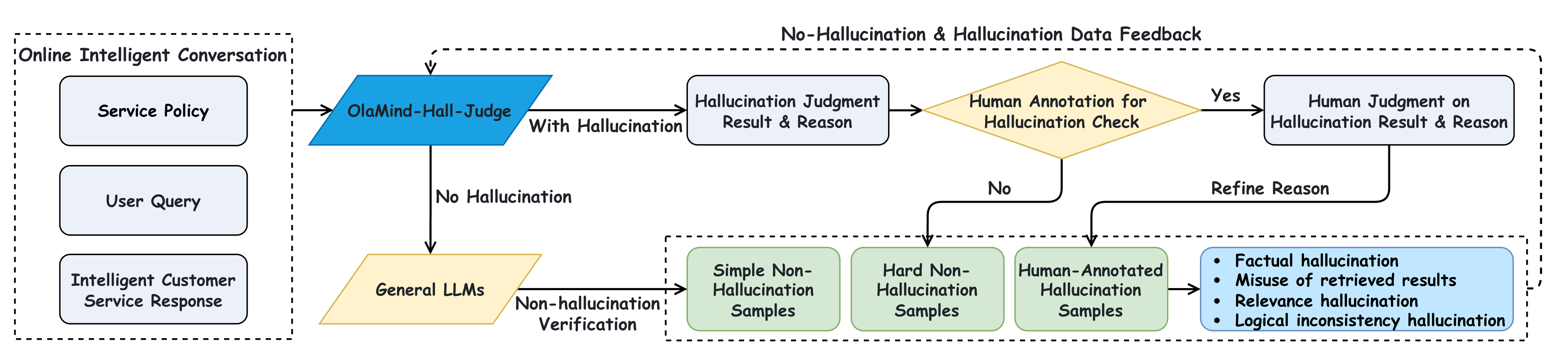
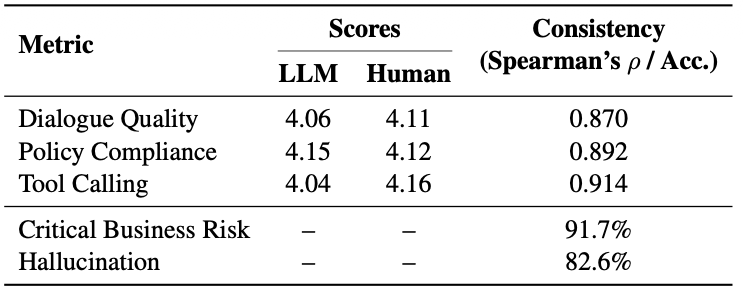
We incorporate a dedicated hallucination-judge model, OlaMind-Hall-Judge, trained through a structured human-LLM interaction pipeline. The system first screens whether a response is hallucinatory, confirms non-hallucination cases with strong general LLMs, and routes suspected hallucinations to human verification. Verified annotations, refined rationales, and hard non-hallucination cases are then used to iteratively improve the detector.
Human Verification
Human experts score 200 randomly sampled instances with the same standards as the LLM judge, and 5,000 human-annotated instances are used for safety evaluation. The agreement is strong across subjective service dimensions, supporting the use of the benchmark as a reliable offline evaluation tool.
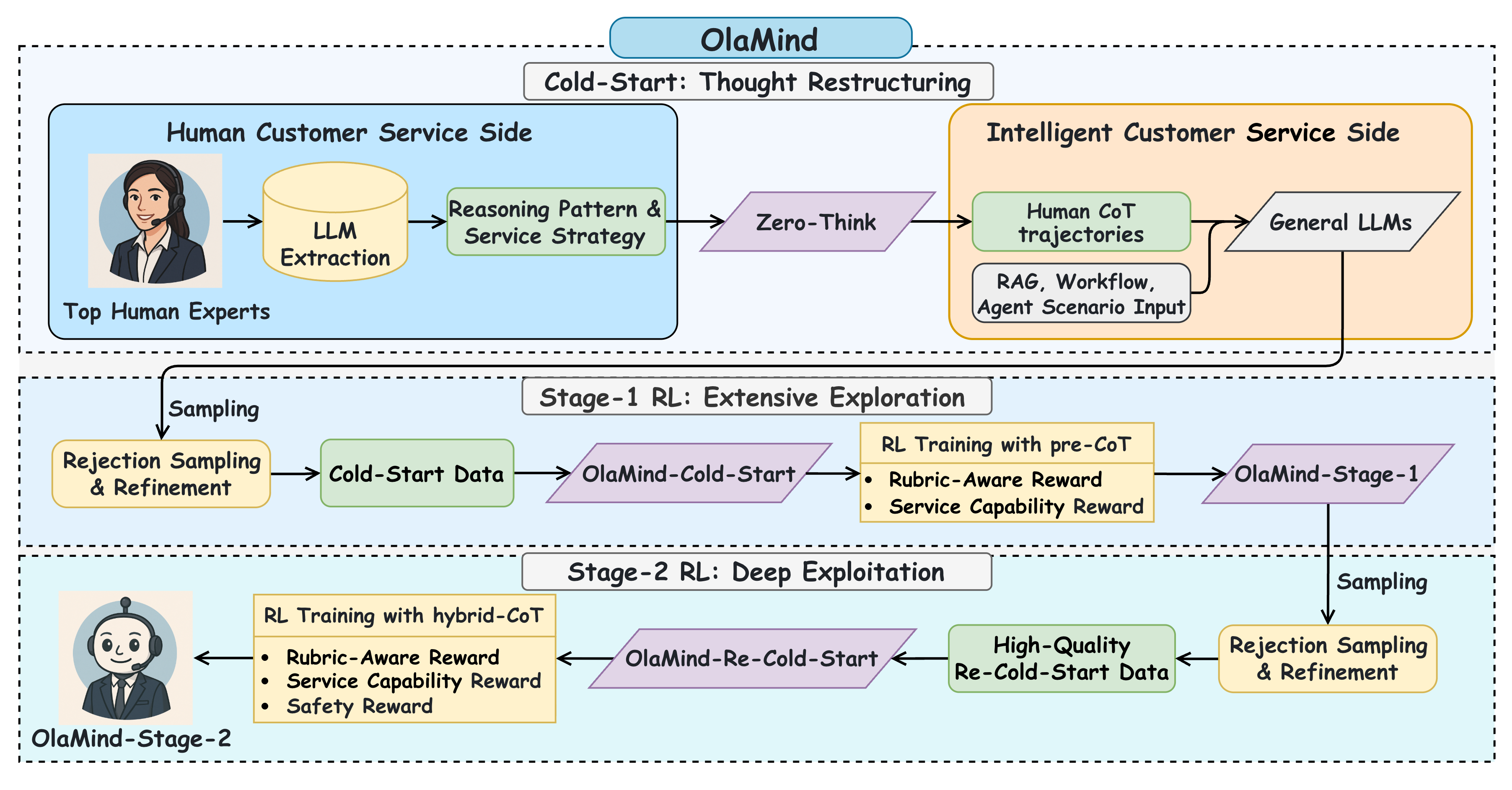
Motivated by evaluations on OlaBench, which reveal that current state-of-the-art LLMs still fall short under industrial customer service constraints, we propose OlaMind, a training paradigm that progressively aligns models with industrial objectives. Instead of direct imitation, it distills reusable reasoning patterns and service strategies from expert dialogues and then adopts an exploration-exploitation refinement scheme.
This stage addresses noisy human data and the instability of directly imitating human responses. Strong general LLMs extract CoT-style trajectories that expose expert reasoning patterns and service strategies, and the resulting data is used to train Zero-Think and OlaMind-Cold-Start.
Starting from OlaMind-Cold-Start, GRPO with pre-CoT training encourages diverse reasoning paths. Rewards combine Dialogue Quality, Policy Compliance, Tool Calling, and a rubric-aware reward with instance-specific weighted criteria.
A re-cold-start step builds higher-quality data, then hybrid-CoT GRPO adds format, length, rule-match, risk, and hallucination rewards. This stage improves safety while preserving reasoning capability for latency-sensitive deployment.

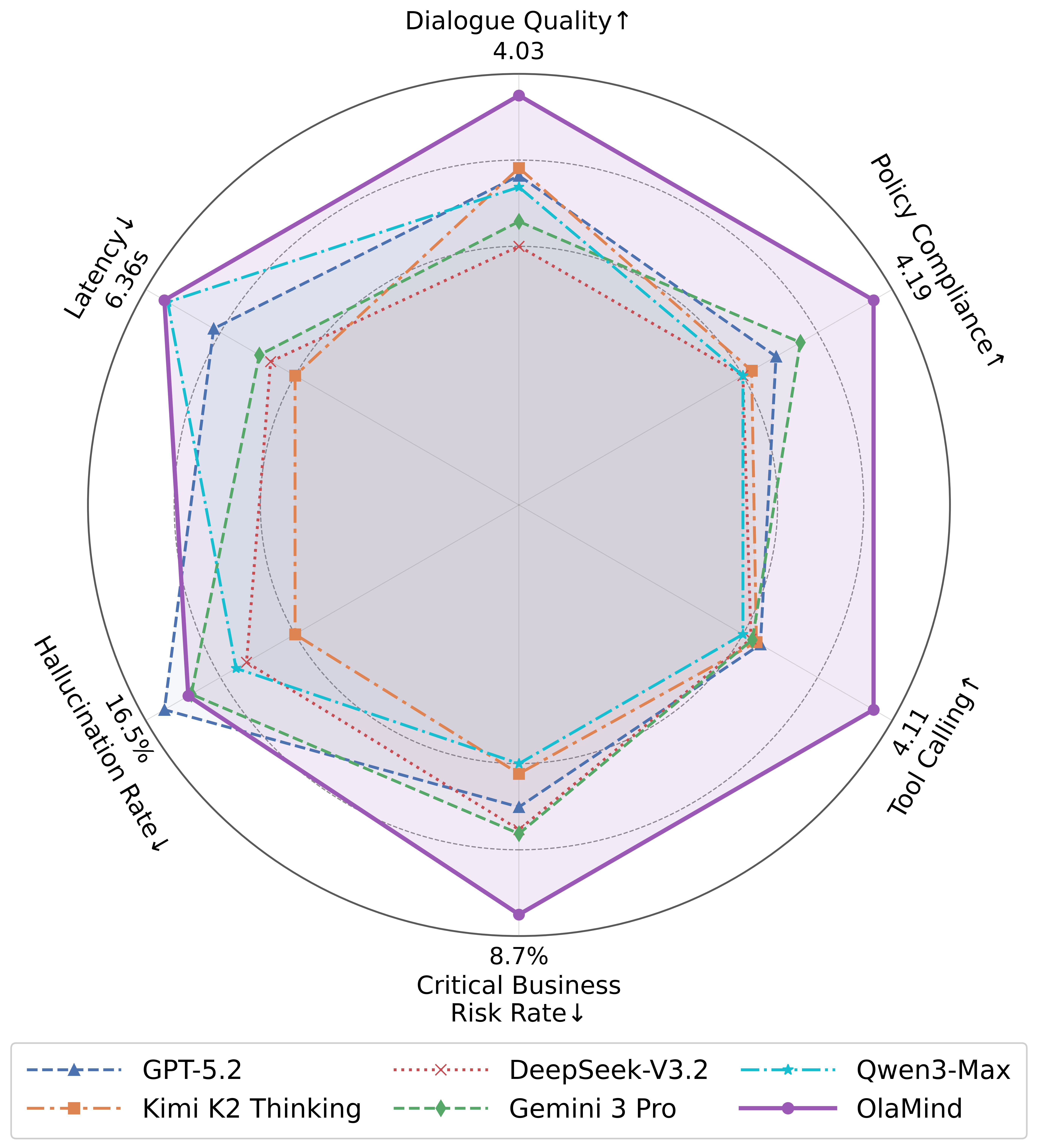
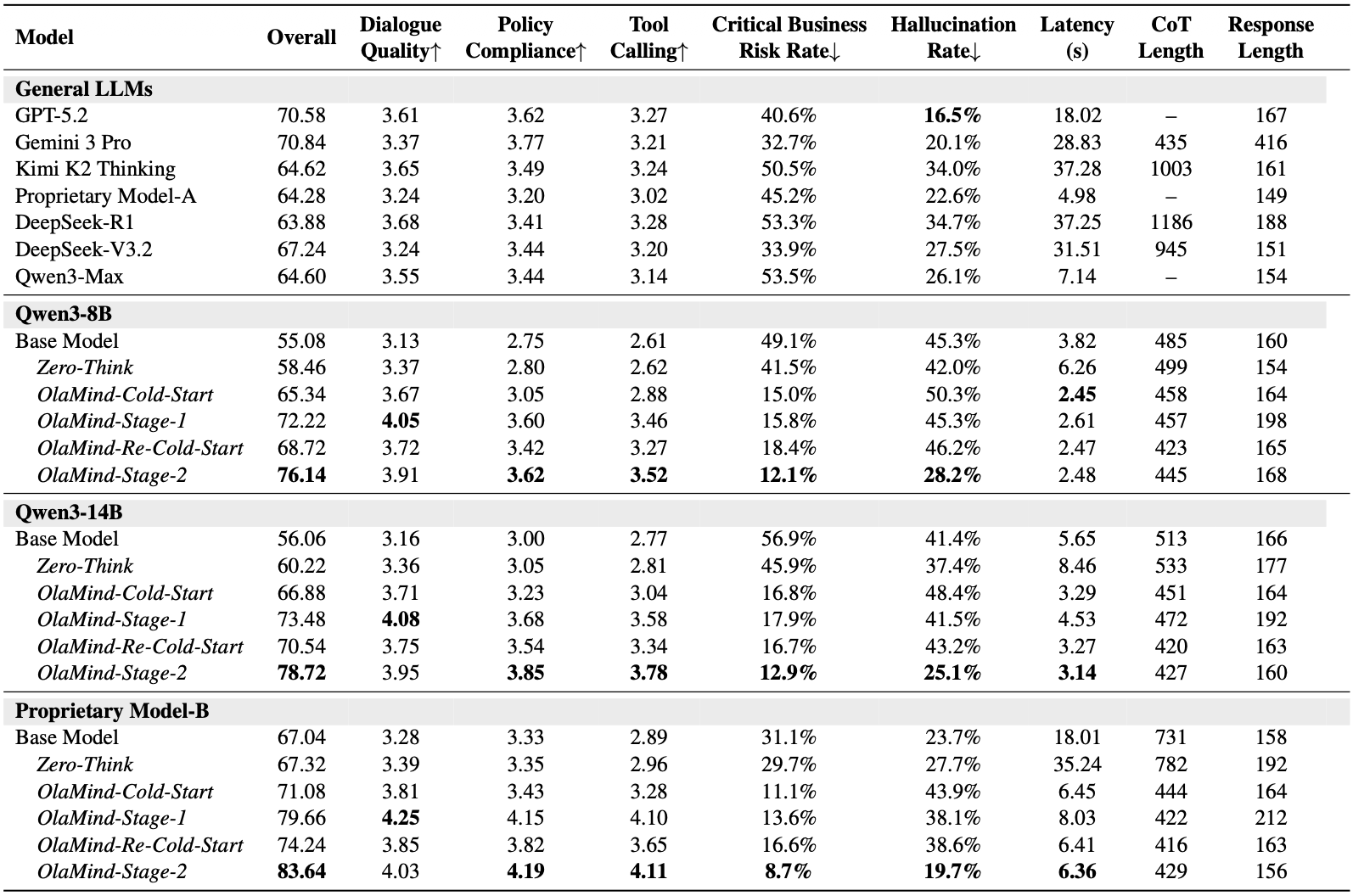
On OlaBench, current state-of-the-art general LLMs still fall short, while OlaMind reaches 83.64 overall and surpasses GPT-5.2 at 70.58 and Gemini 3 Pro at 70.84.
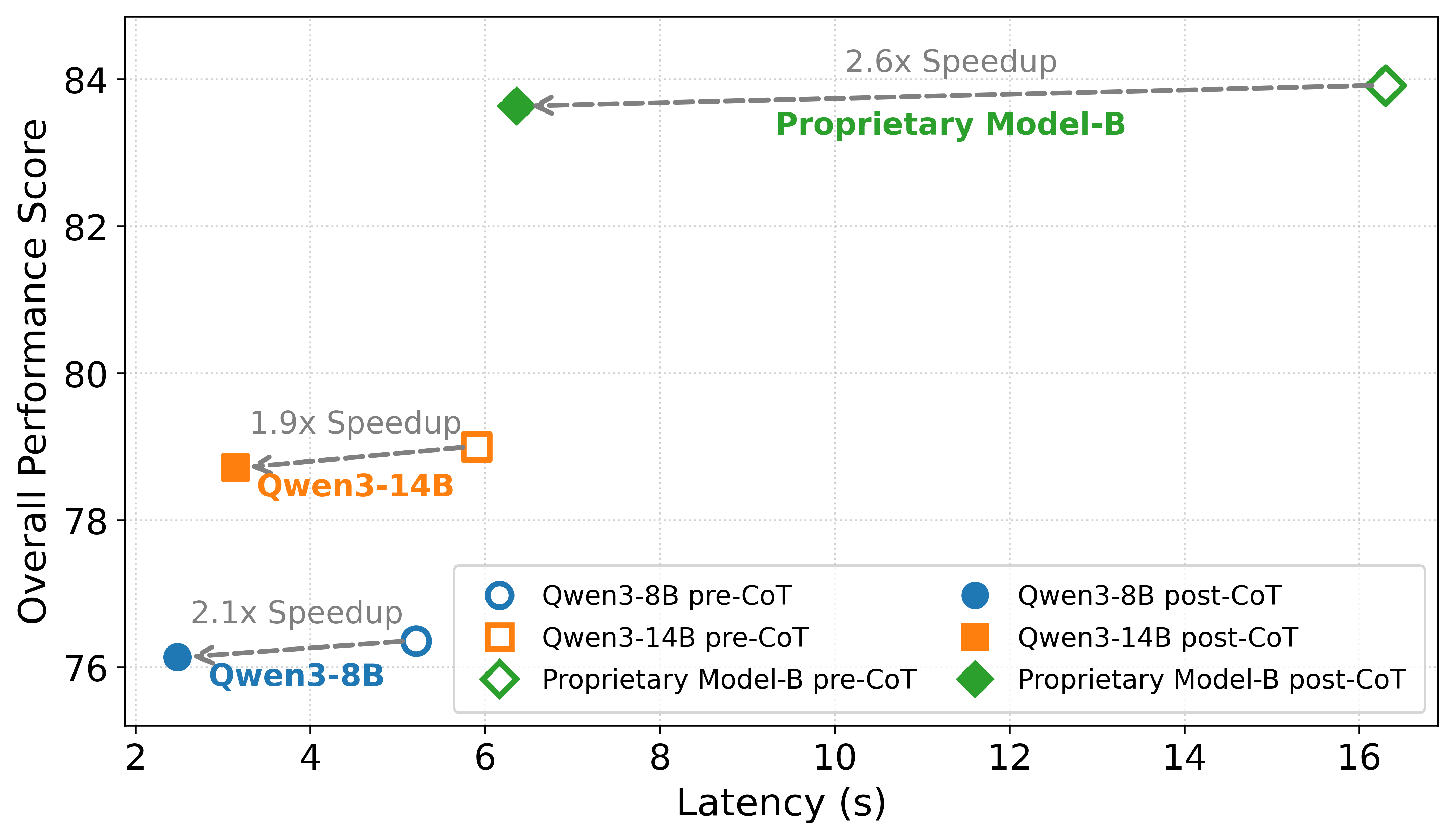
The Pareto plot further highlights the latency-quality trade-offs of post-CoT OlaMind variants.
Ablation Study
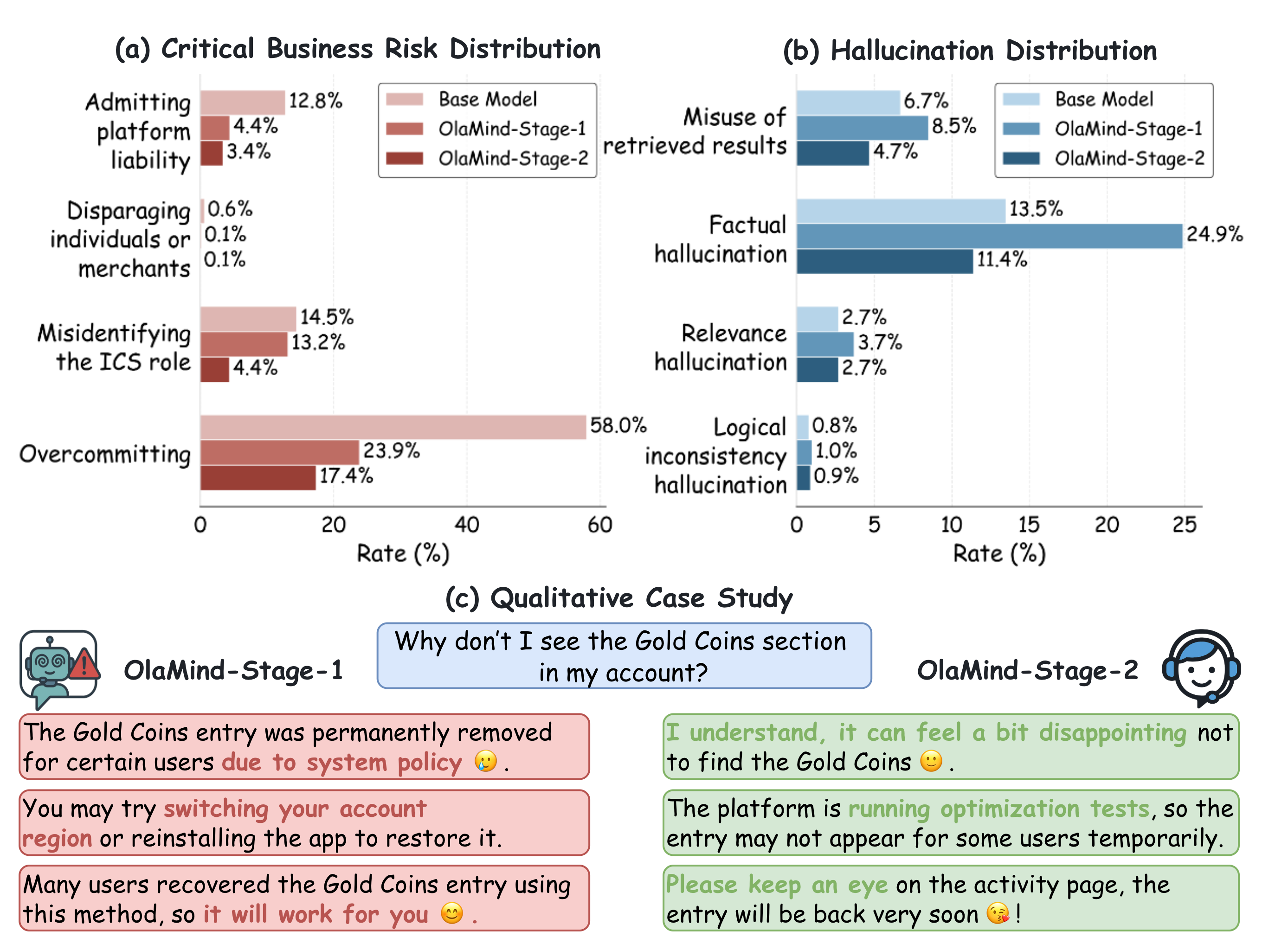
Ablation results show that the final OlaMind performance depends jointly on rubric-aware reward terms, CoT strategy choices, and the staged reinforcement learning design.
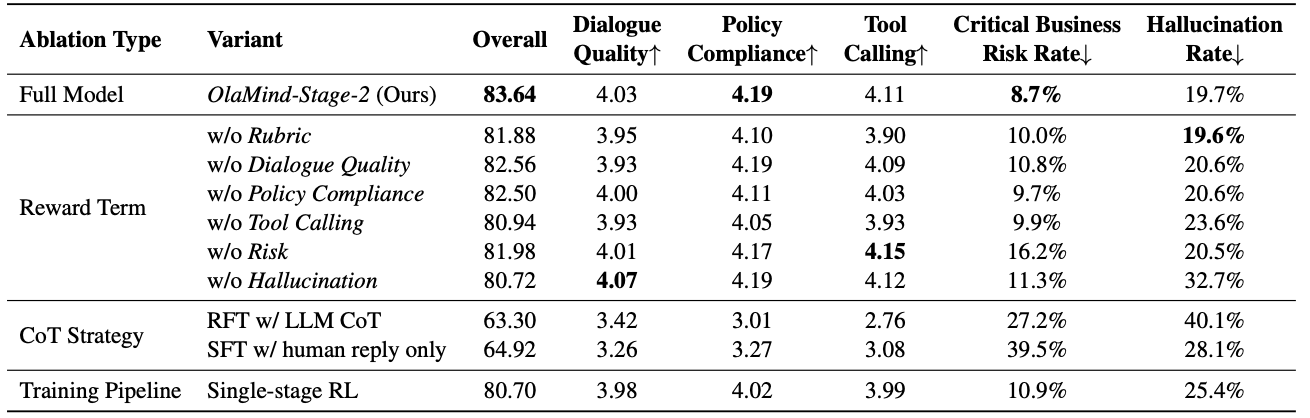
Large-scale online A/B tests confirm that the offline gains transfer to deployment. Across community support and livestream interaction, OlaMind-Stage-2 achieves larger issue-resolution gains and lower human-transfer rates than OlaMind-Cold-Start.
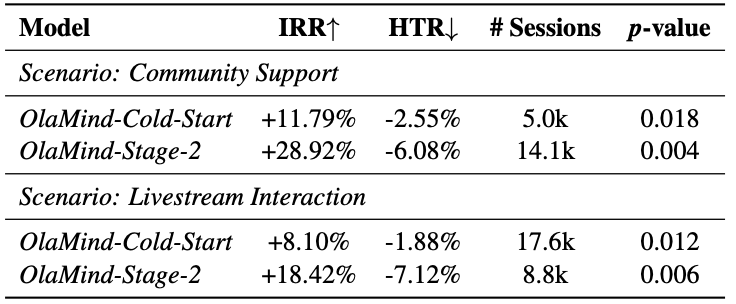
Further analysis shows that Stage-2 corrects the over-exploration behavior of Stage-1, especially by reducing overcommitting risk and factual hallucination. The qualitative case study further illustrates more restrained, policy-consistent responses in ambiguous customer-service scenarios.
@article{gao2025benchmarking,
title={Benchmarking and Learning Real-World Customer Service Dialogue},
author={Gao, Tianhong and Shen, Jundong and Wang, Jiapeng and Shi, Bei and Ju, Ying and Yao, Junfeng and Yu, Huiyu},
journal={arXiv preprint arXiv:2510.22143},
year={2025}
}